Python数据类型详解及分类方法介绍
Python通过数据多少进行分类(python分几类)
简介:本文的主要CTO注释将介绍Python的相关内容,以对Python的数据进行分类。
长(高高的复合体)和浮动(浮动点类型),但Python 3没有更长的时间。
1,int(integer)
机器上的32-bites,整数位的数量为32位,价格范围为-231〜231-1, IE -2147483648〜214748364;
2,长(长完整性)
python长整数没有情况的宽度,但是由于机器内存有限,无法无限。
3,浮点(浮点)
浮动点类型也是小数点的数量,其精度与机器有关。
4,复杂(复数)
python也支持复数数字。
B
是浮动点类型。
两个,string
在pythan中,带引号的瓦尔纳斯被视为字符串。
有两种类型的数据,即STR类型和Unicode类型。
三,布时类型
与其他编程语言一样,python局类型也用于逻辑操作,具有两个值:正确(真实)和错误(错误(错误(假))。
4。
列表
列表是列表中最常见的数据类型。
五,元组
与同一列表相同,这也是一个序列。
)“徽标内部元素由下叶分开。
收集
收集有一个混乱的,不可避免的数据组合。
]
算法过程:
1。
计算原始信息熵。
2。
计算每个样品的每个特征以计算熵。
3。
比较各种特征信息熵的大小,选择信息熵和输出的最便利价格。
Running Results:
Color: 0curinfogain: 2.37744375108baseinfogain: 0.0
Result analysis:根据第一列的细节更好,即,喉节的特征更好。
思考:
1。
它可以使用决定输出样本-Tree算法的最终分类结果吗? 例如样品是男性的1,2,3,是女性。
2。
示例程序生成的决策只是树的一层。
3。
如何判断分类结果的质量?
在下一篇文章中,我将分析并回答以上三个问题。
如果您也有兴趣,欢迎您订阅我的文章,或者您可以在下面发表评论。
整个代码如下:
frommathimportlog
/p>/p>defcalcentropy(dataset):
diclabel = {{{{{{{{{{ } ## tag。
Entrape
Entrapei = 0.0 cnt = len(dataset)
forlabelindiclabel.keys.keys():
dataset = [[1,0,“ yes”],[1,1,“是”],[0,1,“是”],[0,0,“否”,“否” ],[1,0,“否”]
label = [“男性”,“女人”]标签
retsset = [] ##数据集
forcordindaset:
frecold [color] ==值:redeedfeatvec = record [:color]添加到返回到“特征值列表”的列表
returnsate
## ##请参阅最大的信息检测,信息Entrolpe Entrape增长的特征值
###参数:
## dataset:基本数据集
defindbestfeature(dataset):
<numfeatures = len(dataset [dataset [ 0] -RERY特征值baseInfogain = 0.0计算熵
forcolinrange(numFeatures):
unique fore 。
分类数据集的列功能
prob = 1.0*len(subdetz t)/numfeatures ## col colum。
打印“颜色”,“颜色”,“ curinfogain:”,curinfoga in,“ basinfogain:”,basinfogain
ifcurinfogainfogainfogainfogainbaseinfogain:
basinfogain> basinfogain>在returnsinfoga中,bestFeature ###输出最大的信息好处,以获取福利列表
dataset,label = initiataSet()
= FindBestFeature(DataSet)
打印“ BestInfogain:”,Infogain,“ BestFeature:”,“,使用Payathan分析数据(,”,“ BestFeature:” 11)-High -Level -level应用程序类别
本文通常是熊猫交流数据类别的高级别应用程序列中的重复值
a列。
unique()和Value_counts()可以从数组中删除不同的值,并计算其频率
维度表具有不同的值,将主要观察值存储。
数据类别,字典或层次结构
,如果未指定订单,则分类转换是混乱的。
我们可以清楚地指定
如果对特定数据集进行了大量数据分析,请访问CAT直到分类方法
在机器学习或统计数据中,分类数据通常需要要转换为虚拟变量,也称为单热编码
python标准分类?如果我们描述了标准类型,则可以称它们为Python的“基本构建对象原始类型”。
“基本”是指Python提供的这种标准或核心类型。
默认情况下,这些类型的“构建-in”是Python提供的。
因此,“数据”是因为它们用于通用数据存储。
“对象”是因为对象数据和函数的默认值是抽象的。
“原始”是因为这些类型提供了粒度数据存储的较低层。
“类型”是因为它们是数据类型。
但是,以上细节并没有真正告诉您每种类型的工作方式以及它们在世界上可以扮演的角色。
形式发生了什么。
我们还对这种类型的数据的更新以及它们可以提供的存储方式感兴趣。
有三种不同的模型可以帮助我们对基本类型进行分类,并且每个模型都反映了这些类型之间的相互关系。
这些模型可以帮助我们更好地了解类型及其工作原则之间的关系。
结论:主要的CTO注释是关于上述Python的Python的相关内容! 如果您解决了问题,请与更多担心此问题的朋友分享
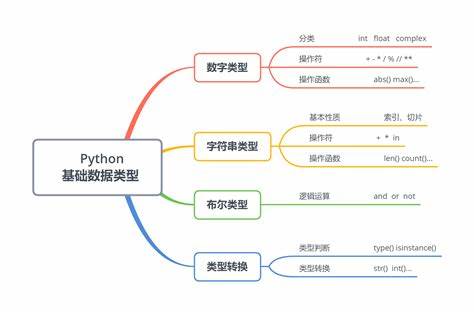
python支持的数据类型主要包括哪几种
Python支持各种数据类型用于不同的信息设置。以下是Python中的主要数据表格: - 验证类型:环境(INT):用于存储肠道(例如100,8080)的区域。
- 用于存储具有小数点的数字类型,例如15.20、0.0,-21.9。
- 复数代表复数a和b-这两个值通常用于所有情况。
2。
(SER):字符串用于在单一或双重经文之间存储文本信息,例如“和平>或“世界”。
PYTO还支持多行字符串和三峰字符串。
3。
列表(列表):列表用于存储多个项目,逗号通过逗号分隔。
该列表是按顺序进行的,可能包含不同的营养素,例如数字,字符串等。
该列表是灵活的,可以更改内容。
4。
Tupl:Tupl:Tupll用于存储许多物品,逗号不同。
与列表不同,税收不变。
创建后,内容将无法更改。
5。
dickrings:字典包含一个钥匙值对的键值对,每个键值都包含一个唯一的键和相应的值。
词典是争议,但钥匙在任何时候都唯一添加或更改。
6。
收集(正确):收集用于存储不同营养素的专业集合。
它不支持收集和支持数据索引,而是提供帐户收集活动,例如存储,类别和差异。
这些物种为Python程序提供了强大的数据处理。
Python中的几种数据类型
通常,Python中的数据类型分为几个类别:数字(数字)包括INT,长,浮动,复杂串,例如:您好,您好,Helloolist [1,2,3,[1,2,3] 4]词典(字典),例如:{1:nihao,2:Hello}元组(Turtle group):(1,2,3,ABC)布尔(布尔)(布尔)(布尔),包括真和错误,因为Python中的所有内容认为一切都是对象,Python不需要像其他一些高级语言那样宣布变量类型。例如,我想用Python设置一个变量i:i = 100c#实现:inti = 100; 长时间歧视,并均匀地使用它。
Python2.x仍然很出色。
以下,以python2.7为例:i = 10Type(i)i = 10000000000000000000000pe(i),那么为什么10 int -1,000,0000000当然,此最大int值与最大int类型231-相关联1,即2147483647,您也可以使用sys.maxint。
2 ** 31-12147483647LSYS.MAXINT2147483647为什么要长的值(在数字后数字表示后数字之后的数字),因为值2 ** 31为2147483648。
此值很长。
精度与机器有关。
例如:i = 10,000.1212Type(i)复杂:紫色类型,特定的含义和使用可以自己显示相关文档。
有三种宣布链式链条的方法:单配件报价,双引号和三个引号(包括三个或三个引号偶引号)。
例如:str1 = helloworldstr2 = helloworldstr3 = helloworldstr4 = hellowordprintr1hellowerordstr2hellowertr2helloworintrinropontrldthon有两种类型的数据链:类型和Unicode。
ASCII编码是由STR类型采用的,这意味着它不能表示托盘。
Unicode类型由Unicode编码使用,该编码可以代表任何字母,包括中文和其他语言。
没有类型的类型python中的类型,即使是一个字母是链式。
ASCII用默认链编码。
例如:str1 = helloprintstr1helostr2 = u中国printstr2通常由项目中的链条操作,编码问题有很多问题。
在处理Python的过程中,我们经常面对三个符号:ASCII,Unicode和UTF-8。
有关指定的简介,请参阅本文。
我的简单理解是用适合英文字母的ASCII绳子。
例如:u = u han printreprr(u)#uu6c49s = u.encode(utf-8)printrepr(s)#xe6xb1x89u2 = s.decode(utf-8)printreprr de string string“ home home”,编码Unicode“ Unicode” U6C49。
转换UTF-8编码后,其编码变为“ XE6XB1X89”。
编码体验的摘要:1。
Python文件加密编码: - * - 图标:UTF-8 - * - 2。
3在系列前面。
任何书面格式。
根据相同文本的编码协调读取异常内容:f = codecs.open(d: /test.txt)contente = f.read()f.close()使用printContent作为以下方法(仅用于托盘):# - * - 编码:utf-8 - * - importcodecsf = codecs.open(d: /test.txt) contente,unicode:printCont.encode(utf-8)printutf-8else:printconth.decode(gbk)。
::nums = [1,2,3,4] type(nums)printnums [1,2,3,4] strs = [hello hello hello trintstrs [hello hellow stras [hello hello hello st = [1,lst = [1,你好,你好,false,false,nums nums strs]类型(LST)printls,-1是最后一个。
它可以在一段时间内达到元素,并支持不同的团队来支持可用于插入和复制数据插入和复制的各种步骤。
3:],四个,4,5]和4 [3:5] = []#[1,2,3,4,5]将第四和第五元素替换为[]以删除[三,四]支持添加lst1 = [Helo,World] lst2 = [良好,时间] praplst1+lst2#[Hello,World,Good,Time] printlst1*5#世界支持世界,你好,世界,你好,你好,你好,你好,你好,你好,可以通过以下方式查看菜单支持的常规方法:[xforxindir([])) defcompare(x,y):return1ifxylse-1#[[[appind] extert element lst = [1,2,3,4,5] lst.append(6)printlst#[1,2,3,3,4,5,6 ] lst.Append(Hello)printlst#[1,2,3,4,5,6]默认X x = lst.pop(0)propx,lst#1 [2,2,2,2,2,2,2,2,2,2,2 ,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,3,4,5,6]删除第一个元素#[原始菜单中出现元素数量的时间。
lstexnd = [Hello,world] lst.exnd(lstexnd)printlst#[2,3,4,5,6,Hello,World]了lstexnd进来#未找到会抛出异常printlst.index(hello)#5#printlst.index(kitty)#valueerror:kittyisnotinlist出现异常#出现异常#【删除列表中的特定元素,如果不存在要删除的元素,则确实存在不存在,它不存在,它不存在,它将给出一个值,而不是异常的返回lst。
转移了#lst.remove(kitty #valueerror:list.remove(x):xnotinlist#(对立)表示反射是正确的,这是菜单元素的布置。
printlst#2] lst.sort()printlst#在排序[2,3,4,5,6,world] nums = [10,5,4,2,3] printnums#[10,5,4,2, 3] nums.sort(比较)printnums#[2,3,4,5,10]菜单转换为ETCUR。
称为SO的重复是一个具有下一个方法的对象(连接时,此方法不需要任何参数)。
调用下一个方法时,迭代器还原其下一个值。
如果调用下一个方法,但没有任何值可以返回,它将导致此停止中断。
重复功能是列表,即重复使用不必同时添加菜单到内存,但可以按顺序访问列表数据。
上述方法仍用于显示作者的一般方法:lst = [1,2,3,4,5] lstiter = iter(lst)print [xforxindir(numiter)ifnotx.startswith(__ __)] [next]接下来只有一种方式。
#print 12345在排名12345的12345中,假肢组的类型是同一列表,也是一个序列。
元组语句如下:lst =(0.1,2,2,2)lst1 =(Hello,)lst2 =(Hello)printType(lst1)#如果您有一个元素,则有一个逗号,否则这将是printType类型类型类型(LST2)#字典类型是一组主要价值对,类似于DistracyDict1 = {} printType(dict1):18} #directlylypirectly inclance anclare dittion type diction dict dict3 = dict = dict(((name,kitty),(年龄),((年龄),(( ,18)。
键)如果字典中存在键(密钥),则在python2.2中输入它,否则它是错误的,但此方法仍然放弃,但仍提供业务界面。
dict.items()返回包含字典(键,值)的列表中的dicteys meta列表 - 包含字典词典中的所有值。
。
dict.pop(键[,虚拟])与get()相似。
未给出,keyError失真是运行的。
dictdefault(键,默认值= nothing)与样式集相似。
dictdefault(键,默认值= nothing)与样式集相似。
布尔类型布尔类型是正确且险恶的,与其他语言中的逻辑类型相同。
Boolete模型值(0)#falseprintbook(1)#trueprintbook(-1)#trueprintbook([])
python支持的数据类型主要包括哪些
在Python贡献的数据类型中,有数字(数字),字符串,列表(列表),元组,元组。1。
数字:Python是整数(INT),花卉类型(浮动),复数类型(复杂)和Bool。
Treed用于存储正值或负数,例如100,-786。
浮点数用于存储浮点数,使用具有十进制因素的数字等。
0.0,-21.9,等等。
使用。
复数类型用于3.14J,45.J,诸如“ J”之类的复数。
“ J”代表虚拟编号。
布尔值用于保存两个值之一。
示例:makefilea = 123#高b = 1.23#浮动-poating -poated -point -point coothed d = true#boothan 2。
String(String) - String(String) - 字符串(String)是Python中的文本类型。
字符串,数字,数字和数字包含特殊字符,例如标点符号符号和python中的引号。
这意味着一旦字符串改变了其内容。
不。
例如,arduinostr1 ='你好,世界“#”“使用弦引用的两个字符串引用。
字符串3。
将变量的变量序列存储在列表(列表)python中。
列表上的元素可能是许多数据,字符串和数字,包括其他列表等。
该列表被方形环包围,逗号与元素分开。
示例:(1,2,3,3,3,5)##ondeger lay lay2 = ['苹果','樱桃'。
0包含不同的数据类型0列表。
不同之处在于,由于差异的差异,并且一旦创建它们,就不可能改变。
不。
乌龟群包围了环,逗号与元素分开。
这些元组通常用于表示相关值,每个值可能是不同的数据类型。
例如,arduinotuple1 =(1,2,3)#(1,2,3)#(1,2,3)#table2 =('Apple')#tuple3 = (1,a',5个数据类型5。
-字典:密钥是存储有价值的值的关键。
例如,主要值是角膜的关键。
30,'newher city'}:'setrwee' - Python曾经用于存储独特的元素。
相关文章

Python C3-MRO算法解析:多重...
2024-12-20 18:53:51
初中生学Python多久合适?Pytho...
2024-12-16 15:26:40
Python字符串与数字转换方法汇总
2024-12-15 03:37:35
Python入门:str函数详解与使用指...
2024-12-20 06:22:40
C语言实现:统计字符串中字符出现频率详解
2024-12-26 04:17:09
Python字符串截取:五种高效方法详解
2024-12-26 13:38:49
Python实现三个整数从小到大排序的几...
2024-12-26 03:23:55
Python编程:实现三位数十位百位互换...
2024-12-16 05:16:08
Python编程:解析三位数正整数的每一...
2024-12-18 10:33:36