Python字符串操作详解:切片技巧与数据类型全面解析
python数据分析题:python中如何取得字符串中某个字符?
答案:s="HelloPython!",s[3:8]="loPy"
答案:
s[3:8]除法表示运算表示取值起始索引(包括匹配值索引)3和结束索引(不包括匹配值索引)8之间。
由于字符串s的第一个字符H的索引值为0,因此索引值字符3为l。
由于空格也算一个字符,所以字符值索引为8t。
最后,取l(含)和t(不含)之间的“loPy”值,即为答案。
补充:
Python使用的切片方法来解决从对象中提取部分值的问题。
例如:对象[start_index:end_index:step]
任何被分割的表达式都包含两个冒号,通常由三个参数start_index、end_index和step分隔。
当只有1个殖民地时,默认第三个参数level=1;
步骤:可以使用正数和负数。
它的绝对值决定了数据切割时的大小程度,正负号决定了切割的方向,负号在右边。
如果省略步长,则默认为1,即从左到右步长1。
start_index:表示起始索引(包括对应的索引值)。
通过省略该模块,对象的结束点表示端点的起点,具体取决于步骤参数的正值或负值。
end_index:结束索引(不包括对应索引的值)。
通过放下模块,检测数据,直到终点也由步骤参数的正值或负值确定。
Python中的几种数据类型
一般来说,Python中的数据类型分为以下几类:Number(数字)包括int、long、float、complexString(字符串)如:hello、hello、helloList(列表)如:[1,2,3]、[1,2,3,[1,2,3],4]Dictionary(字典)例如:{1:nihao,2:hello}Tuple(元组)例如:(1,2,3,abc)Bool(Boolean)包括True和False由于Python中的一切都是对象,因此Python不需要像其他一些高级语言那样主动声明变量的类型。例如,我想将值100赋给变量i。
C#的实现是:inti=100下面简单介绍一下这些数据类型。
数字类型int和long必须连接的原因是int和long。
原因是python3.x之后不再区分int和long,统一使用int。
python2.x还是不一样。
我以Python2.7为例:i=10type(i)i=1000000000type(i)那么为什么10是int,1000000000是long呢?当然,这和int类型的最大值是231-1有关,这与是2147483647,您也可以使用sys.maxint。
2**31-12147483647Lsys.maxint2147483647为什么用上面的方法计算出来的值是long类型(数字后面加‘L’表示是long类型),因为2**31的值是2147483648,是long类型,将length减1,结果仍然是long,但实际上int类型的最大值是2147483647type(2147483647)type(2147483648)float类型float类型与其他钝语言中的浮点数基本相同,都是十进制数,精度与相关机器相同。
例如:i=10000.1212type(i)complex:复数类型具体含义和用法请查看相关文档。
声明字符串类型的字符串有三种方式:单引号、双引号和三引号(包括三个单引号或三个双引号)。
例如:str1=helloworldstr2=helloworldstr3=helloworldstr4=helloworldprintstr1helloworldprintstr2helloworldprintstr3helloworldprintstr4helloworldPython中的字符串有两种数据类型:str类型和unicode类型。
str类型使用ASCII编码,这意味着它不能表示中文。
unicode类型使用unicode编码,可以表示任何字符,包括中文和其他语言。
而且Python中没有像C中那样的char类型,即使是单个字符也是字符串类型。
string默认使用的ASCII编码如果要声明为unicode类型,必须在字符串前添加u或U。
例如:str1=helloprintstr1hellostr2=uChinaprintstr2China由于项目中经常会出现字符串操作,并且由于字符串编码问题而出现很多问题,所以我们先来说说字符串编码问题。
在与Python打交道的过程中,我们经常会遇到三种编码:ASCII、Unicode和UTF-8。
详细介绍请看这篇文章。
我简单的理解是ASCII编码适合英文字符,Unicode适合非英文字符(如中文、韩文等),而utf-8是一种存储和传输格式,是对解码字符(以8位为单位编码)。
例如:u=u汉printrepr(u)#uu6c49s=u.encode(UTF-8)printrepr(s)#xe6xb1x89u2=s.decode(UTF-8)printrepr(u2)#uu6c49说明:声明unicode字符串"中文”,其unicode编码为“u6c49”,经过utf-8编码转换后,其编码变为“xe6xb1x89”。
编码经验总结:1.声明python文件头中的编码格式#-*-coding:utf-8-*-2string3。
对于文件读写操作,建议使用codex.open()而不是内置的open()。
原理,用哪种格式写,用哪种格式读就行,假设一个以ANSI格式保存的文本文件中有一些“汉字”字样,如果直接用下面的代码,在GUI中打印出来或在IDE中(例如,在子文本中,或)。
打印到pydev),会出现乱码或者异常,因为codecs会按照文本本身的编码格式读取内容:f=codecs.open(d:/test.txt)content=f.read()f。
close()printcontent可以改为如下方法(仅适用于中文):#-*-coding:utf-8-*-importcodecsf=codecs.open(d:/test.txt)content=f.read()f.close()ifisinstance(content,unicode):printcontent.encode(utf-8)printutf-8else:printcontent.decode(gbk).encode(utf-8)classlistList类型是a可变集合类型它的元素可以是数字和字符串等基本类型,也可以是列表、元组和字典等集合对象,甚至可以是自定义类型。
定义如下:nums=[1,2,3,4]type(nums)printnums[1,2,3,4]strs=[hello,world]printstrs[hello,world]lst=[1,hello,False,numbers,strs]type(lst)printlst[1,hello,False,[1,2,3,4],[hello,world]]访问按索引列出元素Index从0开始,支持负数最后索引。
lst=[1,2,3,4,5]printlst[0]1printlst[-1]5printlst[-2]4支持除法运算,可以访问元素在一定范围内,支持不同的步长,可以使用分区进行插入和复制数据操作nums=[1,2,3,4,5]printnums[0:3]#[1,2,3]#前三个元素printnums[3:]#[4,5]#后两个元素printnums[-3:]#[3,4,5]#最后三个元素不支持数字[-3:0]numsclone=nums[:]printnumsclone#[1,2,3,4,5]复制操作printnums[0:4:2]#[1,3]步长为2nums[3:3]=[三,四]#[1,2,3,三,四,4,5]在3和4之间输入Numbers[3:5]=[]#[1,2,3,4,5]并将第四个和第五个元素替换为[],这意味着删除[三,四]以支持以下操作加法和乘法lst1=[hello,world]lst2=[good,time]printlst1+lst2#[hello,world,good,time]printlst1*5#[hello方法,world,hello,world,hello,world,hello,world,hello,world]列表支持,可以使用下面的方法从列表中查看支持的公共方法:[xforxindir([])ifnotx.startswith(__)][append,count,extend,index,insert,pop,remove,reverse,sort]defcompare(x,y):return1ifxylese-1#[append]在列表末尾插入lst元素=[1,2,3,4,5]lst.append(6)printlst#[1,2,3,4,5,6]lst.append(你好)printlst#[1,2,3,4,5,6]#[pop]删除一个元素并返回该支持元素的默认值x=lst.pop()printx,lst#hello[1,2,3,4,5,6]#Element默认删除最后一个x=lst.pop(0)printx,lst#1[2,3,4,5,6]删除第一个元素#[count]返回某个元素在printlst中出现的次数。
count(2)#1#[extend]该方法与列表扩展的“+”操作的区别在于该方法修改了原列表,而“+”操作会生成一个新列表lstextend=[hello,world]lstextension(lstextend)printlst#[2,3,4,5,6,hello,world]基于lst扩展lstextend#[index]返回给定值第一次出现的索引位置,将是printlst.index(hello)#5#printls抛出的异常。
printlst#[2,3,4,5,6,world]你好是removed#lst.remove(kitty)#ValueError:list.remove(x):xnotinlist#[reverse]表示反向,表示将列表元素按倒序排列,不打印返回值t#[2,3,4,5,6,world]lst.reverse()printlst#[2,3,4,5,6,world]#[order]顺序printlst#由于以上更改,当前排序为[world,6,5,4,3,2]lst.sort()printlst#Aftersort[2,3,4,5,6,world]nums=[10,5,4,2,3]printnums#[10,5,4,2,3]nums.sort(compare)printnums列表#[2,3,4,5,10]转换为迭代器。
所谓迭代器,就是一个带有另一个方法的对象(这个方法调用时不需要任何参数)。
当调用next方法时,迭代器返回其下一个值。
如果调用next方法,但迭代器没有返回值,则会引发StopIteration异常。
迭代器相对于列表的优点是,使用迭代器不必一次性将列表全部添加到内存中,而是可以顺序访问列表数据。
还是用上面的方法查看迭代器的公共方法:lst=[1,2,3,4,5]lstiter=iter(lst)print[xforxindir(numiter)ifnotx.startswith(__)][next]这是对的,迭代器只有另一种方法,你可以这样做:lst=[1,2,3,4,5]lstiter=iter(lst)foriinrange(len(lst)):printlstiter.next()#按顺序打印12345种元组作为列表,它也是一个序列。
元组声明如下:lst=(0,1,2,2,2)lst1=(hello,)lst2=(hello)printtype(lst1)#如果只有一个元素,后面加一个逗号,否则会是printtypestr(lst2)#字典类型字典类型是键值对的集合,类似于Dictionarydict1={}printtype(dict1)#声明一个空字典dict2={name:kitty,age:18}#声明直接字典类型dict3=dict([(name,kitty),(age,18)])#使用dict函数将列表变成字典dict4=dict(name=kitty,age=18)#使用dict函数通过关键字参数转换为字典dict5={}.fromkeys([name,age])#使用fromkeys函数从键值列表生成字典。
[添加元素]dict1={}dict1[mykey]=helloworld#直接为不存在的键值对赋值并动态添加新元素dict1[(my,key)]=thiskeyisatuple#字典键可以是任意不可变类型,例如数字、字符串、元组等Wait#[键值对的数量]printlen(dict1)#[检查是否包含key]printmykeyindict1#True检查是否包含键为mykey的键值对printhelloindict1#False#[Delete]deldict1[mykey]#删除我的键键值对继续使用上面的方法查看所有公共字典方法:[xforxindir({})ifnotx.startswith(__)][清除、复制、fromkeys、get、has_key、items、iteritems、iterkeys、itervalues、keys、pop、popitem、setdefault、更新、值、viewitems、viewkeys、viewvalues]dict.clear()删除字典中的所有元素dict.copy()返回字典的副本(浅拷贝)dict.get(key,default=None)返回字典中key的key对应的值dict返回默认值(注意def参数ault的默认值为None)dict.has_key(key)如果字典中存在该key则返回True,否则返回False。
在Python2.2中引入in和notin之后,这个方法几乎被废弃了。
它仍然提供一个工作界面。
dict.items()返回一个包含字典中一些(键,值)对的列表dict.keys()返回一个包含字典中键的列表dict.values()返回一个包含字典中所有值的列表dict.iter的iteritems()、iterkeys()和itervalues()方法与它们的非迭代对应物,只不过它们返回迭代器而不是列表。
dict.pop(key[,default])与get()方法类似。
引发KeyError异常。
dict.setdefault(key,default=None)与set方法类似(如果字典中不存在该key,则从dict[key]=default中为其赋值。
dict.setdefault(key,default=None)与set方法类似(如果字典中不存在key键,则从dict[key]=default中为其赋值。
布尔类型布尔类型True和False,本质上与中的布尔类型相同其他语言。
下面列出了典型的布尔值printbool(0)#Falseprintbool(1)#Trueprintbool(-1)#Trueprintbool([])#Falseprintbool(())#Falseprintbool({})#Falseprintbool()#Falseprintbool(None)#Efake
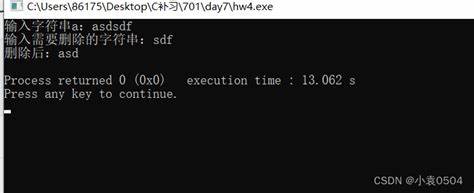
\n在python中怎么用
\n在Python中使用:
1.“\n”是换行符,表示换行符
2“\\”表示反斜杠(\)
3。
“\t”代表制表符
4.'\"'代表双引号
含义
换行符与其他字符没有什么区别由于换行符始终是最后一个字符,因此可以直接选择删除'最后一个字符中的所有字符,只x='abc\n'x[:-1].也可以使用字符串的strip方法,但是strip方法也会使用py去掉换行符,中文编码声明注释:#coding=gbk,函数:len()函数:返回字符串、列表、字典、元组等的长度语法:len(str参数:str:string、list、dictionary、tuple、等)返回值:字符串、列表、字典等的长度。
python新手请教,用python取字符串中最后的一个特定字符之前的字符串,谢谢了
相关文章

Python ASCII码转换与十六进制...
2024-12-15 12:29:11
Python快速统计文本词频,助你轻松掌...
2025-01-17 16:42:44
Python输出文件保存与XML字符串参...
2024-12-14 15:08:00
Python中pow函数:高效计算指数的...
2025-03-07 04:47:33
Python 3.9.5 安装教程:Wi...
2025-03-06 12:58:36
Python字符串去重技巧:replac...
2024-12-15 02:00:49
Python编程技巧:轻松计算1-500...
2024-12-29 03:29:57
Python多行输入输出与数据合并技巧解...
2024-12-28 14:34:13
Python四种内置数据类型详解及区别对...
2024-12-16 13:30:30